Array and hash table are probably the most important data structures. Some programming languages such as Perl, Lua and Javascript, almost build the language core on top of the two data structures. While array is straightforward to implement, hash table is not. This is why we have paid continuous efforts in improving the hash table performance. This blog post reviews recent techniques not commonly found in classical textbooks.
Open addressing vs. chaining
This is not an advanced topic at all, but it is worth emphasizing: for small keys, open addressing hash tables are consistently faster and smaller than a standard chaining based hash tables. C++11 requires std::unordered_map to use chaining, which means if you want an efficient hash table for lots of small keys, choose another library. Some of the techniques below are applied to open addressing only.
Secondary hash functions
A hash function is bad if it often maps distinct keys to the same bucket. A hash function can also be bad if it follows a pattern. One example is the identity hash function, which maps any integer to itself. When you insert N adjacent integers to the table, inserting an integer colliding with one of the existing numbers may trigger an O(N) operation, much slower than the expected O(1). To reduce the effect of such hash functions, we can introduce a second hash function that maps one integer to another more random one. This blog post recommends the following:
static inline uint64_t fibonacci_hash(uint64_t hash) {
return hash * 11400714819323198485llu;
}
This belongs to the larger category of multiplicative hash functions. It is a good choice on modern CPUs that implement fast integer multiplications.
Using a secondary hash function is like a safe guard. When users choose good hash functions, this secondary function only wastes time, a little bit.
Caching hash values
When we use long strings as keys, comparing two keys may take significant time. This comparison is often unnecessary. Note that the hash of a string is a good summary of the string. If two strings are different, their hashes are often different. We can cache the hash and only compare two keys when their hashes are equal. It is possible to implement the idea with any hash table implementations. We only need to change the key type like
typedef struct {
uint64_t hash;
char *str;
} HashedStr;
#define hs_hash_func(a) ((a).hash)
#define hs_equal(a, b) ((a).hash == (b).hash && \
strcmp((a).str, (b).str) == 0)
static void hs_fill(HashedStr *p, const char *str) {
p->str = strdup(str);
p->hash = my_string_hash_func(p->str);
}
Writing all these in user’s code is a little complicated. Some hashtable libraries provide options to cache hashes inside the library. It is a handy feature.
Quadratic probing and power-of-2 table size
This is not an advanced technique, either, but it seems that not everyone knows the following. The textbook I used over 15 years ago mentioned that quadratic probing may never visit some cells. To see that, you can run this:
void main(void) {
int i, b = 10, n = 1<<b, *c = (int*)calloc(n, sizeof(int));
for (i = 0; i < n; ++i) {
int x = i * i & (n - 1);
if (c[x]++) printf("hit: %d\n", i);
}
}
You will see 852 "hit" lines. This means even if the table has empty slots, quadratic probing may not find a place to put a new element. The wiki said: “there is no guarantee of finding an empty cell once the table gets more than half full, or even before the table gets half full if the table size is not prime.”
If you go to that wiki page, you will find the phrase ahead of the quoted sequence is “With the exception of the triangular number case for a power-of-two-sized hash table”. This was added in 2012. By “triangular”, we mean to change line 4 above to:
int x = i * (i + 1) / 2 & (n - 1);
When you run the program again, you won’t see any “hit” lines. You can find a proof here, which is in fact an exercise in Knuth’s book. In all, the “half-full limitation” is largely a myth.
Robin Hood & Hopscotch hashing
Robin Hood hashing and Hopscotch hashing can be considered as extensions to Cuckoo hashing. Different from traditional solutions to hash collisions, they may displace a key in the hash table if the probe length is too long.
In the words of wiki, with Robin Hood hashing, “a new key may displace a key already inserted, if its probe count is larger than that of the key at the current position”. It reduces the variance in searching keys and makes the table still efficient under a high load factor. Robin Hood hashing is gaining popularity. Several of the fastest hash table libraries, including Rust’s standard library, is using this strategy.
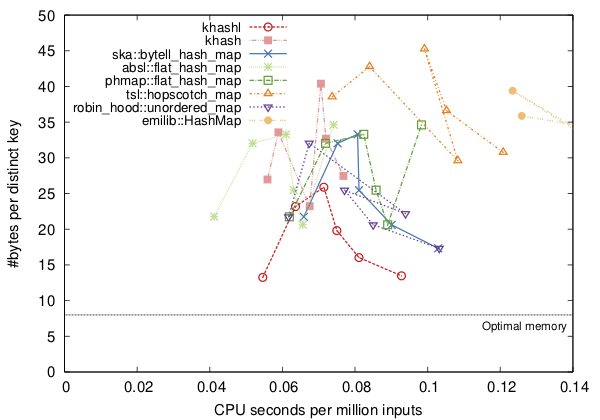
However, Robin Hood hashing is not universally better. First, insertion may be a little slower due to swaps of keys. Second, with an extra counter, each bucket is larger, which partly cancels the advantage under high load. In my benchmark, Robin Hood hashing is not obviously better on that particular task. A Google’s Abseil developer also commented that they tried Robin Hood hashing, but found it is not that impressive.
Hopscotch hashing generally follows a similar philosophy. I will not go into the very details. I just point out in my benchmark, this strategy is not clearly better, either (see this figure).
Swiss table
Swiss table is the name of Google’s new hash table absl::flat_hash_map and is explained in this video. It uses a meta-table to indicate if a bucket is empty or has been deleted before. khash.h uses a similar table, but Swiss table does it better: it uses two bits one bit to keep empty/deleted and six seven bits to cache hash values, such that most of time it can find the right bucket without querying the main bucket table. And because this meta-table is small (one byte per element), we can query 16 cells with a few SSE instructions.
I thought Swiss table could easily beat my khash.h at the cost of a little bit more memory. However, it doesn’t. I will look into this at some point.
Apparently inspired by the Swiss table, ska::bytell_hash_map also employes a one-byte-per-element meta-table, but instead of caching 6-bit of hash values, it uses the lower seven bits to calculate the distance to the next bucket (details remain unknown). This implementation achieves very good space-time balance.
Concluding remarks
There is not a universally best hash table library. Each library has to choose a balance between space and speed. I am yet to see a library that beats the rest in both aspects. As a matter of fact, there is probably not a fastest hash table library, either. Strategies fast at query may be slow at insertions; strategies fast for large keys may be overkilling for small keys.
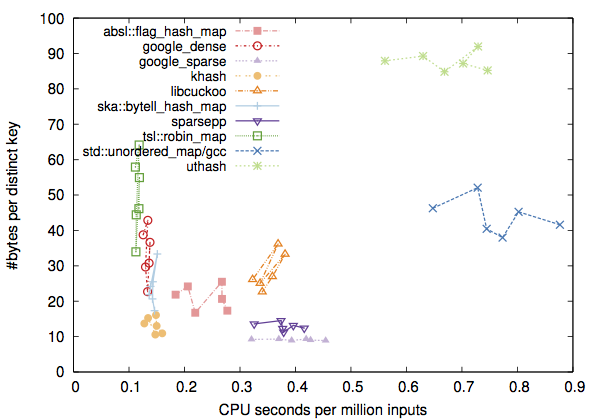
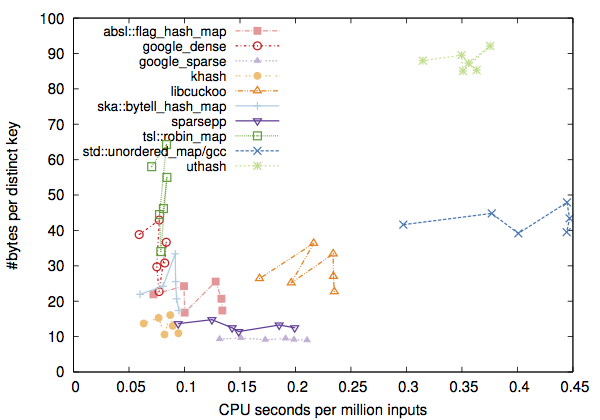
However, some hash tables can be consistently faster and smaller than others. According to my recent evaluation, ska::flat_hash_map, ska::bytell_hash_map, tsl::robin_map and tsl::hopscotch_map are wise choices to C++11 programmers, at least for small keys. They are fast, standalone and relatively simple. Google’s absl::flat_hash_map is ok, but I thought it could be faster. Google’s dense_hash_map and my khash.h remain top options for C++98 and C, respectively.
Update: Swiss table caches 7 bits of hash in the meta-table, not 6 bits. Fixed a few typos.

{kind=link}
{kind=link}
{kind=link}